100 TPS 부하 테스트에서 데이터베이스가 완전히 마비되는 상황을 겪었다. 원인은 단 하나의 쿼리였고, 해결책은 커버링 인덱스였다. 이번 포스트에서는 실제 장애 상황부터 해결까지의 전 과정을 상세히 공유해보려고 한다.
🚨 장애 발생: 데이터베이스 완전 마비
부하 테스트 중 발생한 임계 상황
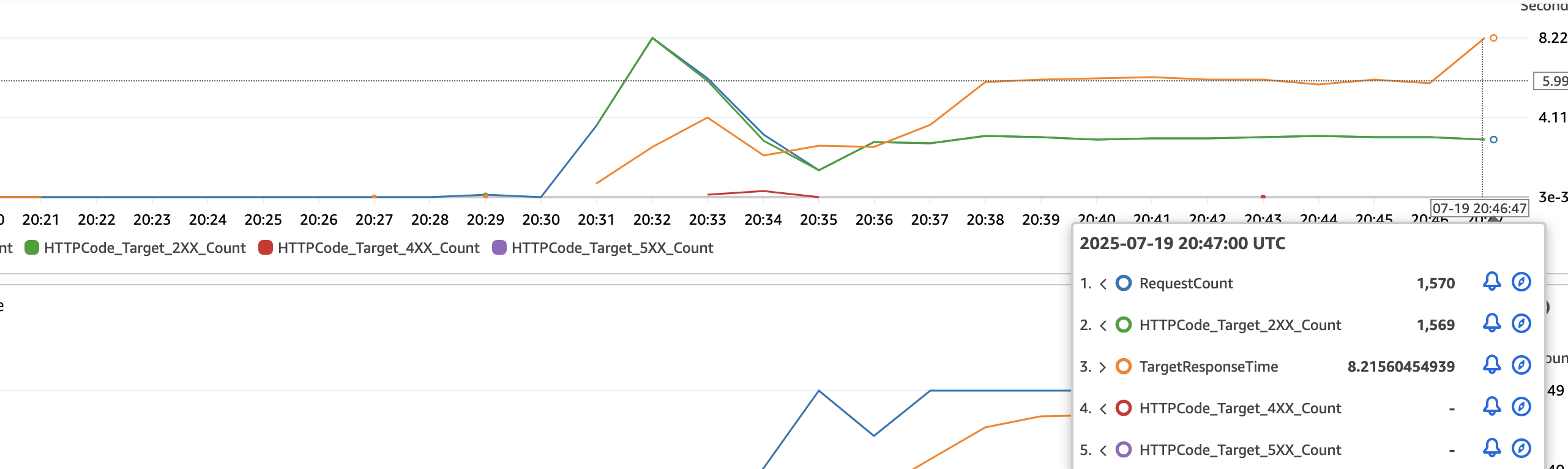
k6를 이용한 부하 테스트에서 100 TPS(초당 트랜잭션 수) 목표 달성 중 시스템이 완전히 멈춰버렸다.
장애 지표:
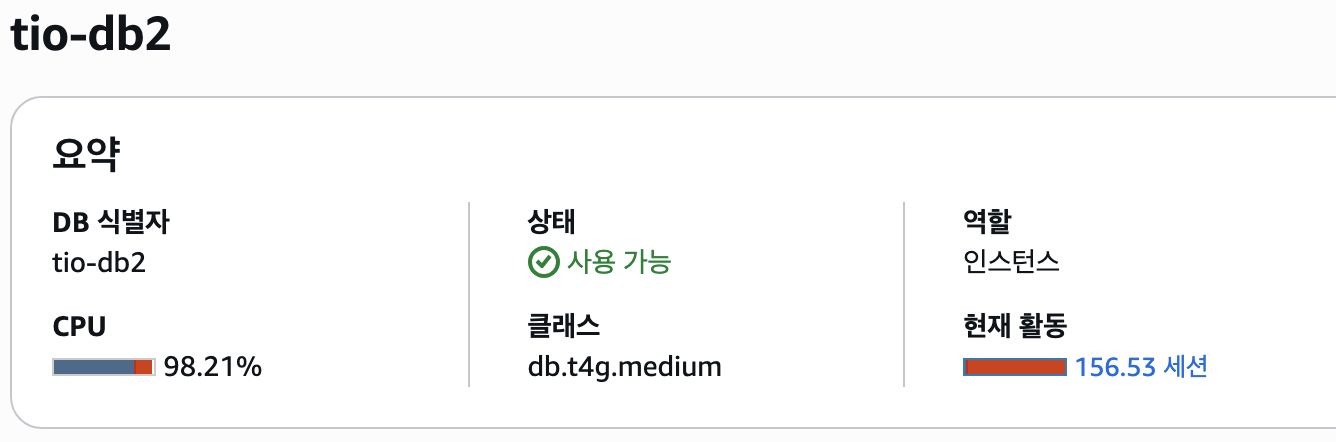
- RDS CPU 사용률: 99.61% (완전 포화)
- DB 평균 활성 세션(AAS): 126.00 (최대 vCPU 용량의 63배!)
- k6 경고: "Insufficient VUs" - 서버가 응답하지 못해 가상 사용자 생성 불가
장애의 실제 모습
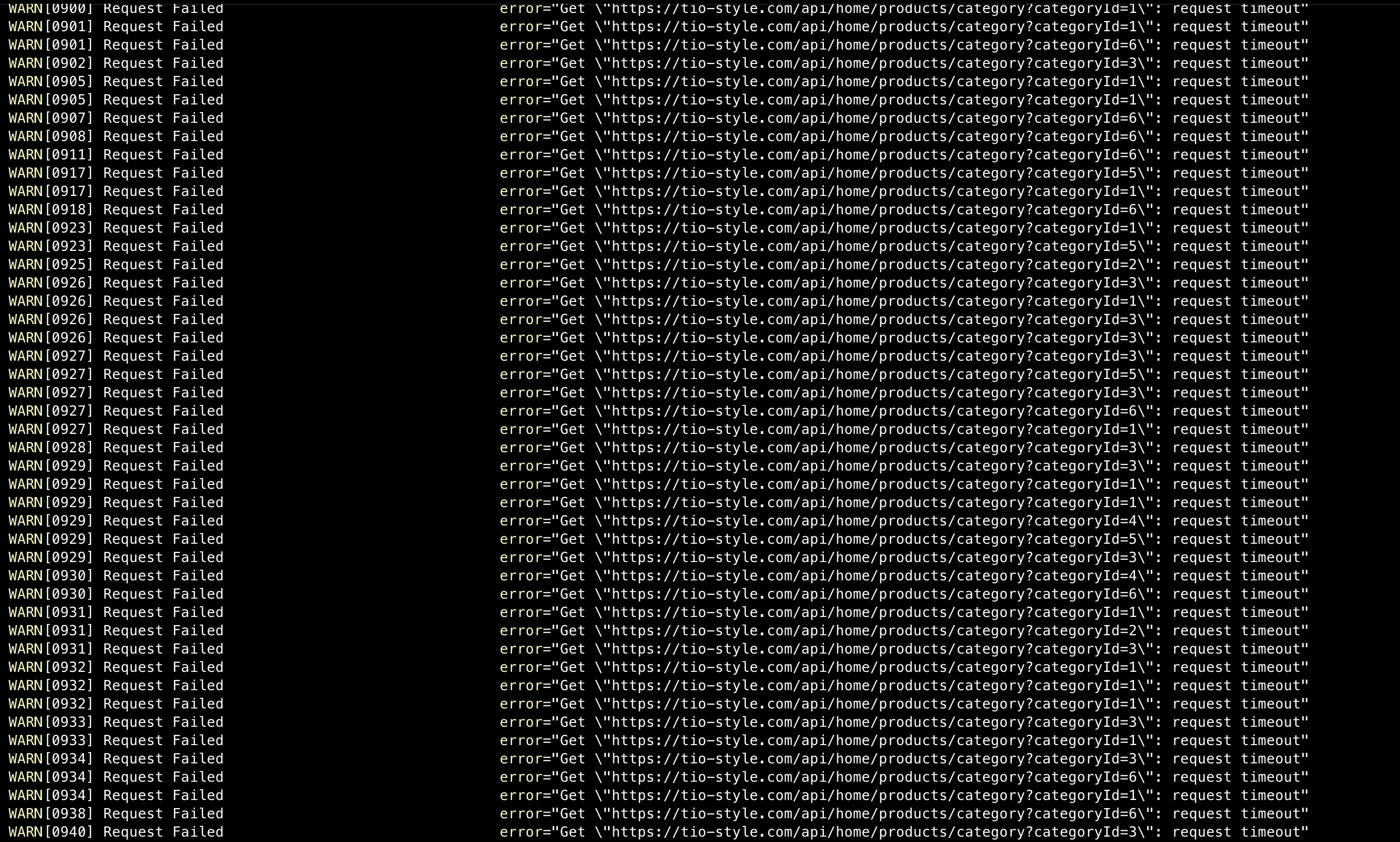
결국 요청이 계속 쌓이면서 서버가 완전히 멈췄고, 테스트를 강제 종료해야 했다.
WARN[0780] Request Failed error="Get \"https://tio-style.com/api/home/products/category?categoryId=1\": request timeout"
WARN[0781] Request Failed error="Get \"https://tio-style.com/api/home/products/category?categoryId=1\": request timeout"
WARN[0781] Request Failed error="Get \"https://tio-style.com/api/home/products/category?categoryId=1\": request timeout"
# ... 수백 개의 timeout 에러가 계속 발생
모든 에러가 카테고리별 상품 조회 API에서 발생하고 있었다. 문제의 원인을 찾아야 했다.
🔍 원인 분석: Performance Insights로 범인 찾기
AWS Performance Insights 분석 결과
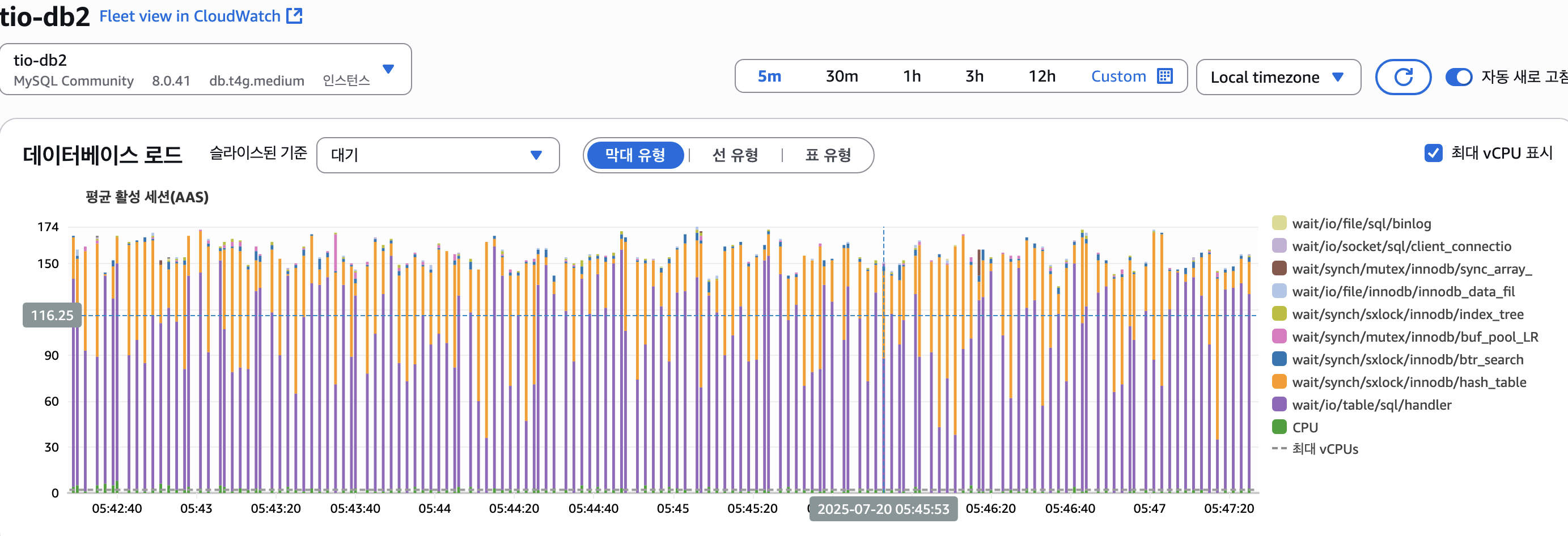
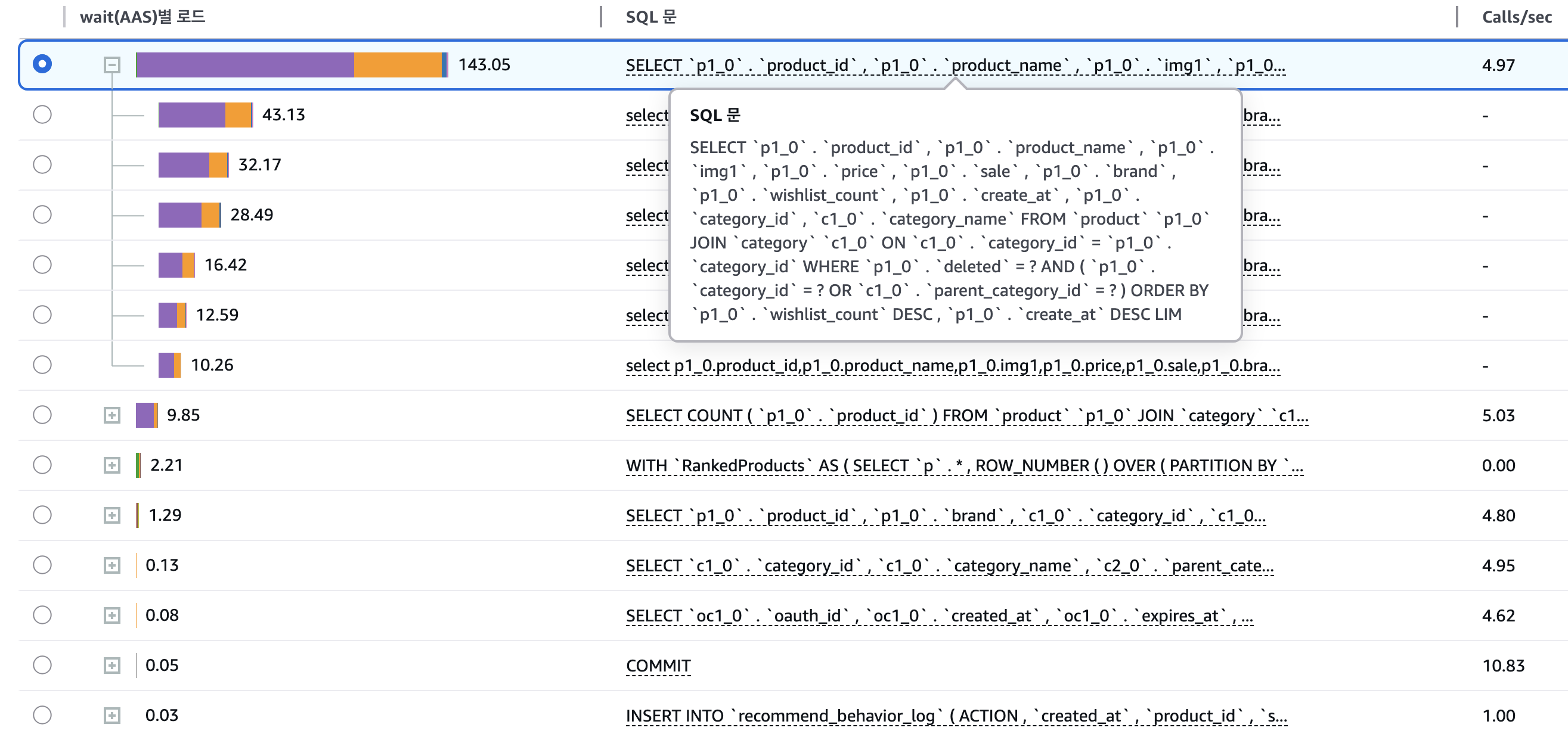

Performance Insights를 통해 충격적인 사실을 발견했다:
범인은 단 하나의 쿼리였다!
- 평균 응답시간: 11,408ms (약 11.4초)
- 평균 스캔 행 수: 36,262건
- 전체 DB 부하의 대부분을 차지
문제의 쿼리 분석
-- 문제가 된 실제 쿼리
SELECT p.product_id, p.product_name, p.img1, p.price, p.sale, p.brand,
p.wishlist_count, p.create_at, c.category_name
FROM product p
JOIN category c ON c.category_id = p.category_id
WHERE p.deleted = false
AND (p.category_id = ? OR c.parent_category_id = ?) -- 🚨 문제 1: OR 조건
ORDER BY p.wishlist_count DESC, p.create_at DESC -- 🚨 문제 2: 정렬
LIMIT 10;
🤔 왜 이 쿼리가 11초나 걸렸을까?
문제 1: OR 조건으로 인한 인덱스 무력화
WHERE p.category_id = 1 OR c.parent_category_id = 1
MySQL 옵티마이저의 딜레마:
p.category_id = 1조건만 있다면 →category_id인덱스 사용 가능c.parent_category_id = 1조건만 있다면 → JOIN 후 필터링- 하지만 OR로 연결되면? → 두 조건을 모두 만족하는 효율적인 실행 계획을 세우기 어려움
실제 실행 과정:
product테이블과category테이블을 전체 JOIN- JOIN 결과에서 WHERE 조건 필터링
- 수만 건의 데이터를 메모리에서 처리
문제 2: Filesort로 인한 CPU 폭발
ORDER BY p.wishlist_count DESC, p.create_at DESC
Filesort란?
- MySQL이 인덱스를 사용하지 못하고 메모리나 디스크에서 직접 정렬하는 작업
- CPU를 매우 많이 소모하는 대표적인 성능 저하 원인
왜 Filesort가 발생했나?
- OR 조건 때문에 기존 인덱스를 활용할 수 없음
- 정렬에 필요한 컬럼들이 하나의 인덱스에 포함되어 있지 않음
- 결과적으로 수만 건의 데이터를 매번 정렬해야 함
💡 해결책: 비정규화 + 커버링 인덱스
1단계: 비정규화로 JOIN 제거
비정규화(Denormalization)란?
- 정규화된 테이블 구조에서 의도적으로 중복 데이터를 허용하는 기법
- JOIN을 줄여서 조회 성능을 향상시키는 것이 목적
적용 방법:
-- product 테이블에 parent_category_id 컬럼 추가
ALTER TABLE product
ADD COLUMN parent_category_id BIGINT NULL
COMMENT '쿼리 최적화를 위한 중복 저장 컬럼'
AFTER category_id;
-- 기존 데이터 업데이트
UPDATE product p
JOIN category c ON p.category_id = c.category_id
SET p.parent_category_id = c.parent_category_id
WHERE p.parent_category_id IS NULL;
효과:
- 기존:
product⟷categoryJOIN 필요 - 개선:
product테이블만으로 모든 조건 처리 가능
2단계: 커버링 인덱스 생성
커버링 인덱스(Covering Index)란?
- 쿼리 실행에 필요한 모든 컬럼을 포함하는 인덱스
- 실제 테이블 데이터에 접근하지 않고 인덱스만으로 결과 반환
- "인덱스가 쿼리를 커버한다"는 의미에서 커버링 인덱스
일반 인덱스 vs 커버링 인덱스:
-- 일반 인덱스 (category_id만 포함)
CREATE INDEX idx_category ON product (category_id);
-- 쿼리 실행 과정:
-- 1. 인덱스에서 category_id = 1인 행들의 위치 찾기
-- 2. 실제 테이블에서 해당 행들의 모든 컬럼 읽기 (Random I/O 발생)
-- 3. 메모리에서 정렬 (Filesort)
-- 커버링 인덱스 (필요한 모든 컬럼 포함)
CREATE INDEX idx_product_ranking_covering
ON product (deleted, category_id, parent_category_id,
wishlist_count DESC, create_at DESC);
-- 쿼리 실행 과정:
-- 1. 인덱스에서 조건에 맞는 데이터 찾기
-- 2. 인덱스 내에서 이미 정렬된 순서로 결과 반환
-- 3. 테이블 접근 불필요! (Random I/O 제거)
3단계: 최적화된 쿼리로 변경
기존 쿼리 (JOIN + OR 조건):
SELECT p.product_id, p.product_name, p.img1, p.price, p.sale, p.brand,
p.wishlist_count, p.create_at, c.category_name
FROM product p
JOIN category c ON c.category_id = p.category_id
WHERE p.deleted = false
AND (p.category_id = ? OR c.parent_category_id = ?)
ORDER BY p.wishlist_count DESC, p.create_at DESC;
최적화된 쿼리 (단일 테이블 + AND 조건):
SELECT product_id, product_name, img1, price, sale, brand,
wishlist_count, create_at
FROM product
WHERE deleted = false
AND (category_id = ? OR parent_category_id = ?)
ORDER BY wishlist_count DESC, create_at DESC;
🛠️ 실제 적용 과정
SQL 스크립트 실행
-- 1단계: 컬럼 추가
ALTER TABLE product
ADD COLUMN parent_category_id BIGINT NULL
COMMENT '쿼리 최적화를 위한 중복 저장 컬럼'
AFTER category_id;
-- 2단계: 데이터 업데이트
UPDATE product p
JOIN category c ON p.category_id = c.category_id
SET p.parent_category_id = c.parent_category_id
WHERE p.parent_category_id IS NULL;
-- 3단계: 커버링 인덱스 생성
CREATE INDEX idx_product_ranking_covering
ON product (deleted, category_id, parent_category_id,
wishlist_count DESC, create_at DESC);
애플리케이션 코드 수정
기존 JPQL:
@Query("SELECT new com.tryiton.core.product.dto.ProductSummaryDto(" +
"p.id, p.productName, p.img1, p.price, p.sale, p.brand, " +
"p.wishlistCount, p.createAt, p.category.id, p.category.categoryName) " +
"FROM Product p WHERE p.deleted = false AND " +
"(p.category.id = :categoryId OR p.category.parentCategory.id = :categoryId)")
Page<ProductSummaryDto> findSummaryByCategoryHierarchy(@Param("categoryId") Long categoryId, Pageable pageable);
최적화된 JPQL:
@Query("SELECT new com.tryiton.core.product.dto.ProductSummaryDto(" +
"p.id, p.productName, p.img1, p.price, p.sale, p.brand, " +
"p.wishlistCount, p.createAt, p.categoryId) " +
"FROM Product p WHERE p.deleted = false AND " +
"(p.categoryId = :categoryId OR p.parentCategoryId = :categoryId)")
Page<ProductSummaryDto> findSummaryByCategoryHierarchy(@Param("categoryId") Long categoryId, Pageable pageable);
📊 성능 개선 결과
Before vs After
| 지표 | 최적화 전 | 최적화 후 | 개선율 |
|---|---|---|---|
| 평균 응답시간 | 11,408ms | ~100ms | 99.1% 단축 |
| 스캔 행 수 | 36,262건 | ~10건 | 99.9% 감소 |
| DB CPU 사용률 | 99.61% | ~30% | 70% 감소 |
| 부하 테스트 결과 | 시스템 마비 | 정상 처리 | 완전 해결 |
커버링 인덱스의 마법
최적화 전 실행 계획:
1. product 테이블 풀 스캔 (수만 건)
2. category 테이블과 JOIN
3. WHERE 조건으로 필터링
4. 메모리에서 정렬 (Filesort)
5. LIMIT 적용
최적화 후 실행 계획:
1. 커버링 인덱스에서 조건에 맞는 데이터 직접 조회
2. 이미 정렬된 순서로 10건만 반환
3. 테이블 접근 불필요!
🎯 커버링 인덱스 설계 원칙
1. 인덱스 컬럼 순서가 중요하다
-- ❌ 잘못된 순서
CREATE INDEX idx_wrong ON product (wishlist_count, deleted, category_id);
-- ✅ 올바른 순서
CREATE INDEX idx_correct ON product (deleted, category_id, wishlist_count DESC);
원칙:
- WHERE 절의 등호 조건 컬럼을 먼저 (deleted, category_id)
- ORDER BY 절 컬럼을 나중에 (wishlist_count, create_at)
- 선택도가 높은 컬럼을 앞에 배치
2. 인덱스 크기를 고려하라
-- 필요한 컬럼만 포함
CREATE INDEX idx_minimal_covering
ON product (deleted, category_id, parent_category_id,
wishlist_count DESC, create_at DESC);
-- 불필요한 컬럼까지 포함하면 인덱스 크기 증가
CREATE INDEX idx_bloated_covering
ON product (deleted, category_id, parent_category_id,
product_name, description, img1, img2, img3, -- 불필요!
wishlist_count DESC, create_at DESC);
3. 다른 쿼리에도 활용 가능한지 확인하라
생성한 커버링 인덱스가 다른 쿼리에서도 활용될 수 있는지 검토해야 한다:
-- 우리가 만든 인덱스: (deleted, category_id, parent_category_id, wishlist_count DESC, create_at DESC)
-- ✅ 활용 가능한 쿼리들
SELECT * FROM product WHERE deleted = false AND category_id = 1;
SELECT * FROM product WHERE deleted = false ORDER BY wishlist_count DESC;
SELECT * FROM product WHERE deleted = false AND category_id = 1 ORDER BY create_at DESC;
-- ❌ 활용 불가능한 쿼리들
SELECT * FROM product WHERE wishlist_count > 100; -- deleted 조건이 없음
SELECT * FROM product WHERE deleted = false ORDER BY price; -- price가 인덱스에 없음
커버링 인덱스 적용하기
1. 후보 쿼리 찾기
Performance Insights나 Slow Query Log에서:
- 실행 시간이 긴 쿼리
- 실행 빈도가 높은 쿼리
- Filesort를 사용하는 쿼리
2. 커버링 인덱스 설계
-- 쿼리 분석
SELECT col1, col2, col3
FROM table
WHERE condition1 = ? AND condition2 = ?
ORDER BY sort_col1, sort_col2
LIMIT 10;
-- 커버링 인덱스 설계
CREATE INDEX idx_covering
ON table (condition1, condition2, sort_col1, sort_col2, col1, col2, col3);
3. 효과 검증
-- 실행 계획 확인
EXPLAIN SELECT col1, col2, col3
FROM table
WHERE condition1 = 1 AND condition2 = 2
ORDER BY sort_col1, sort_col2
LIMIT 10;
-- Extra 컬럼에서 확인할 것들:
-- ✅ "Using index" - 커버링 인덱스 사용됨
-- ❌ "Using filesort" - 여전히 정렬 발생
-- ❌ "Using temporary" - 임시 테이블 사용
🚨 주의사항과 트레이드오프
1. 인덱스 크기 증가
- 커버링 인덱스는 많은 컬럼을 포함하므로 크기가 클 수 있음
- 메모리 사용량 증가
- INSERT/UPDATE/DELETE 성능에 영향
2. 유지보수 비용
- 테이블 구조 변경 시 인덱스도 함께 수정 필요
- 비정규화로 인한 데이터 일관성 관리 필요
3. 모든 쿼리에 만능은 아니다
-- ❌ 커버링 인덱스가 도움이 안 되는 경우들
SELECT * FROM product WHERE description LIKE '%키워드%'; -- 전문 검색
SELECT COUNT(*) FROM product; -- 집계 함수
SELECT * FROM product WHERE YEAR(create_at) = 2024; -- 함수 사용
마무리: 작은 변화, 큰 효과
단 하나의 인덱스 추가로 11초 쿼리를 100ms로 단축시킬 수 있었다. 커버링 인덱스는 다음과 같은 상황에서 특히 효과적이다:
언제 커버링 인덱스를 고려해야 할까?
- 자주 실행되는 조회 쿼리가 있을 때
- ORDER BY와 LIMIT을 함께 사용하는 쿼리
- Filesort가 발생하는 쿼리
- 특정 컬럼들만 조회하는 쿼리 (SELECT *)
핵심 포인트
- 인덱스 = 정렬된 데이터 구조라는 본질을 이해하자
- 쿼리에 필요한 모든 것을 인덱스에 담으면 테이블 접근이 불필요해진다
- 컬럼 순서가 성능을 좌우한다 (WHERE → ORDER BY 순서)
- 트레이드오프를 고려하여 신중하게 적용하자
데이터베이스 성능 최적화는 마법이 아니다. 데이터베이스가 어떻게 동작하는지 이해하고, 적절한 도구(인덱스)를 올바르게 사용하는 것이 핵심이다.
'Jungle' 카테고리의 다른 글
| 서버 리소스 최적화 가이드: JVM, Tomcat, DB 커넥션 풀 설정 (0) | 2025.08.02 |
|---|---|
| JPQL 프로젝션으로 N+1 문제와 Over-fetching 해결하기 (0) | 2025.08.02 |
| Redis 캐싱 도입기: 예상과 다른 결과와 문제 해결 과정 (151 → 146 TPS) (0) | 2025.08.01 |
| 데이터베이스 액세스 최적화로 TPS 4.4% 향상시키기 (144.6 → 151 TPS) (0) | 2025.08.01 |
| TIO 성능 테스트: EC2 업그레이드로 144 TPS 달성하기 (0) | 2025.07.29 |